既然在使用搜索引擎的时候会涉及到使用分词器,那么我们肯定是要指定去使用分词器。那么指定分词器有两种方式,第一种是在创建索引的时候指定分词器,另外一种是在创建mapping字段上指定分词器,下面我们分别演示一下:
一、在创建索引的时候指定分词器
put /test
{
"mappings": {
"properties": {
"description": {
"type": "text"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis.analyzer.default.type": "ik_smart"
}
}
}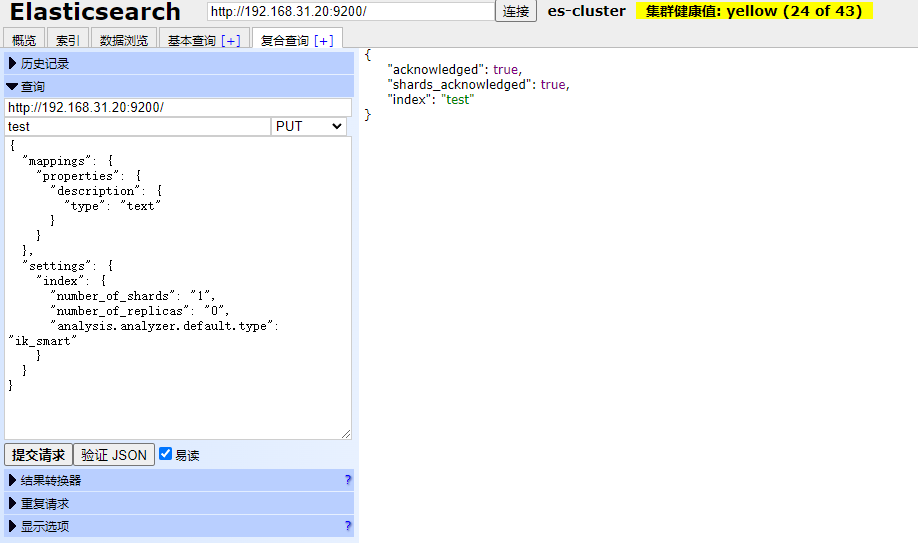
此时我们在全局上创建了ik_smart的分词器(需要提前在elasticsearch中安装ik分词器),此时当前这个test索引里面所有类型为text的字段,都会按照ik_smart的方式进行分词。我们测试一下:
post /test/_analyze
{
"text": "中华人民共和国"
}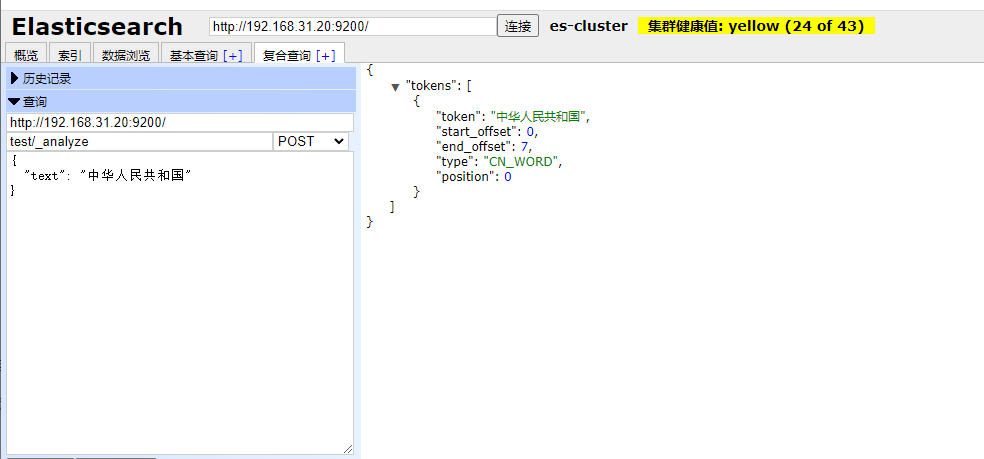
可以看到这里整个test索引都是使用ik_smart进行分词。
这种在setting里面设置分词器会在全局生效,当前索引里面只要是text类型都将全部使用指定的分词方式(这里指定是ik_smart)。
这种全局的方式比较适合动态创建mapping的场景。
二、在创建mapping的时候指定分词器
这里就是在指定的字段上指定分词器,没有指定的字段会使用系统默认的分词器,指定的方式也很简单,例如:
put /test
{
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "ik_max_word"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}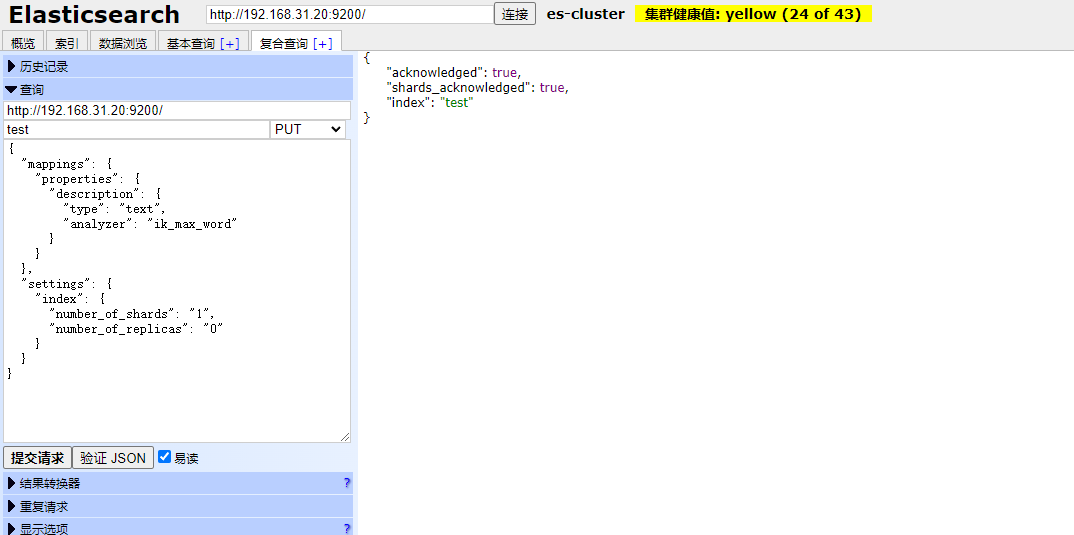
此时可以看到我们是在某个字段里面添加的,那么分词器仅对当前的字段生效。
备注:
1、第二种方式是我们在生产环境中经常使用到的添加分词器的方式。

搜索使用场景优化手段")








还没有评论,来说两句吧...