我们知道flink这块是属于分布式计算框架,因此在实际计算的时候,会把整个job切分成很多的task,然后把一部分task聚集到A worker节点上执行,某些task聚集到B worker节点上执行。这就是整个分布式计算的实际情况。
那么有时候我们会涉及到一些job的操作,对于job来说我们知道job的话,小结果job大结果的时候,sql执行效率最高。那么在flink job里面我们同样可以利用这样的思想,也就是把小结果数据集首先分发到各个worker节点上,当worker节点真正执行的时候,就可以直接从本地的worker节点获取小结果,直接进行job计算。这就是我们介绍的分布式缓存。
首先我们来个代码案例看看情况,背景如下:
我们首先把学生id和对应的成绩做成一个小文件,作为缓存的文件,然后在计算的时候,根据学生的id和缓存文件来拼接学生的信息。
具体操作步骤如下:
1、制作学生成绩文件
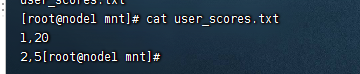
这里的话,我们模拟制作学生的成绩文件,创建一个名为user_scores.txt的文件,然后把下面的内容复制进去:
1,20 2,5
2、把user_scores.txt文件上传到hdfs上
这里既然是分布式计算,所以缓存文件我们不能用本地,不然的话得把文件挨个上传到所有的节点上去,此时我们最好用的就是hdfs文件系统,我们把这个user_scores.txt文件上传到hdfs上,
hadoop fs -put user_scores.txt /users/
上传完成之后,我们就可以在hdfs上看到这个文件了:

3、编写代码
这里我们直接上代码,然后再分析代码逻辑。
首先是DataSetDistributeCacheJob,完整的代码示例如下:
package org.example;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.example.func.DistributeCacheMapper;
public class DataSetDistributeCacheJob {
public static void main(String[] args) throws Exception{
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Integer> input = env.fromElements(2, 1);
// 从hdfs上读取文件
env.registerCachedFile("hdfs://192.168.31.218:8020/users/user_scores.txt", "user_scores");
DataSet<String> result = input.map(new DistributeCacheMapper());
result.print();
}
}这里我们使用了一个DistributeCacheMapper,这里的mapper其实就是会在各个节点执行的task,详细代码如下:
package org.example.func;
import org.apache.commons.io.FileUtils;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import java.io.File;
import java.nio.charset.Charset;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class DistributeCacheMapper extends RichMapFunction<Integer, String> {
private static final Map<Integer,String> users = new HashMap<Integer,String>();
@Override
public void open(Configuration parameters) throws Exception {
File userScores = getRuntimeContext().getDistributedCache().getFile("user_scores");
List<String> list = FileUtils.readLines(userScores, Charset.forName("UTF-8"));
for(String v : list){
String[] tokens = v.split(",");
users.put(Integer.valueOf(tokens[0]),tokens[1]);
}
super.open(parameters);
}
@Override
public String map(Integer integer) throws Exception {
String score = users.get(integer);
return integer+":"+score;
}
}以上就是完整的代码,我们来介绍下完整的流程。
1、在ExecutionEnvironment创建的时候,我们就需要注册这里的分布式缓存文件,给定registerCachedFile一个文件的地址和文件的自定义名称。
2、在需要使用到分布式文件的时候,根据前面给定的自定义名称来获取对应的文件:getRuntimeContext().getDistributedCache().getFile("user_scores");
3、获取到文件之后,我们读取文件,然后解析相关的结果作为本地的缓存。
4、利用flink获取的实时数据与本地的缓存进行job,匹配出最后的结果。最后我们来看看运行的结果:

结果里面完整的实现了job的效果。很好的利用了分布式缓存的知识点。
最后按照惯例,附上本案例的源码,登录后即可下载。

的超时时间或者重试次数")






还没有评论,来说两句吧...