上一篇文章《Dinky 实时计算平台系列(十八)FlinkSql作业开发之快速演示》我们在dinky中进行了一个简单的演示开发,从现在开始,我们切合实际情况,做一些flink多数据源的connector方面的开发,本文主要演示的是FlinkSql对接kafka的开发。下面直接开始
1)部署一个kafka
这里我们需要找一个kafka进行安装一下,本站kafka的安装文章比较多,具体可参考本文《Docker-compose的方式快速部署kafka单机环境》。
2)下载flink-kafka驱动
在前面我们可以看到我们使用的Dinky依赖的flink版本是1.17版本的

所以这里的话,我们需要下载一个flink1.17版本的kafka-connector。这里flink1.17版本的kafka-connector的下载地址是:Flink1.17-kafka-connector下载。
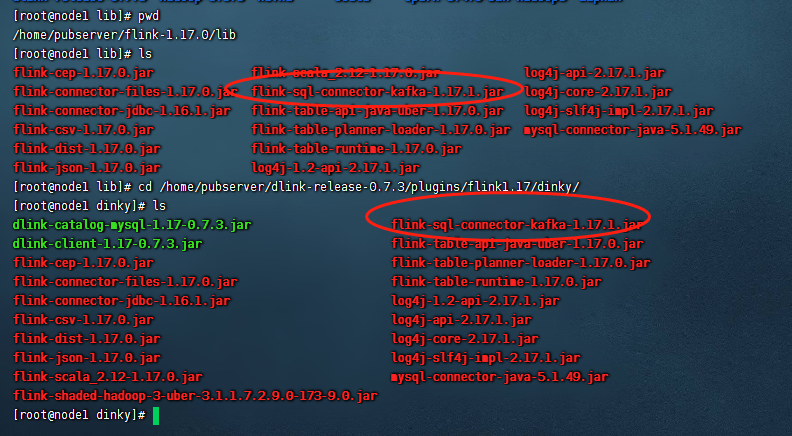
下载之后这里的jar包全称为:flink-sql-connector-kafka-1.17.1.jar
然后我们把这个jar包分别放到如下的两个目录里面去:${Dinky_HOME}/plugins/flink1.17/dinky/和${Flink_home}/lib/目录下,如下图:
3)进入kafka,创建一个topic
这里我们进入到kafka的bin目录下,创建一个名为user的topic,创建命令如下:
kafka-topics.sh --create --bootstrap-server 192.168.31.218:9092 --replication-factor 1 --partitions 1 --topic user
4)进入dinky编写flinksql作业
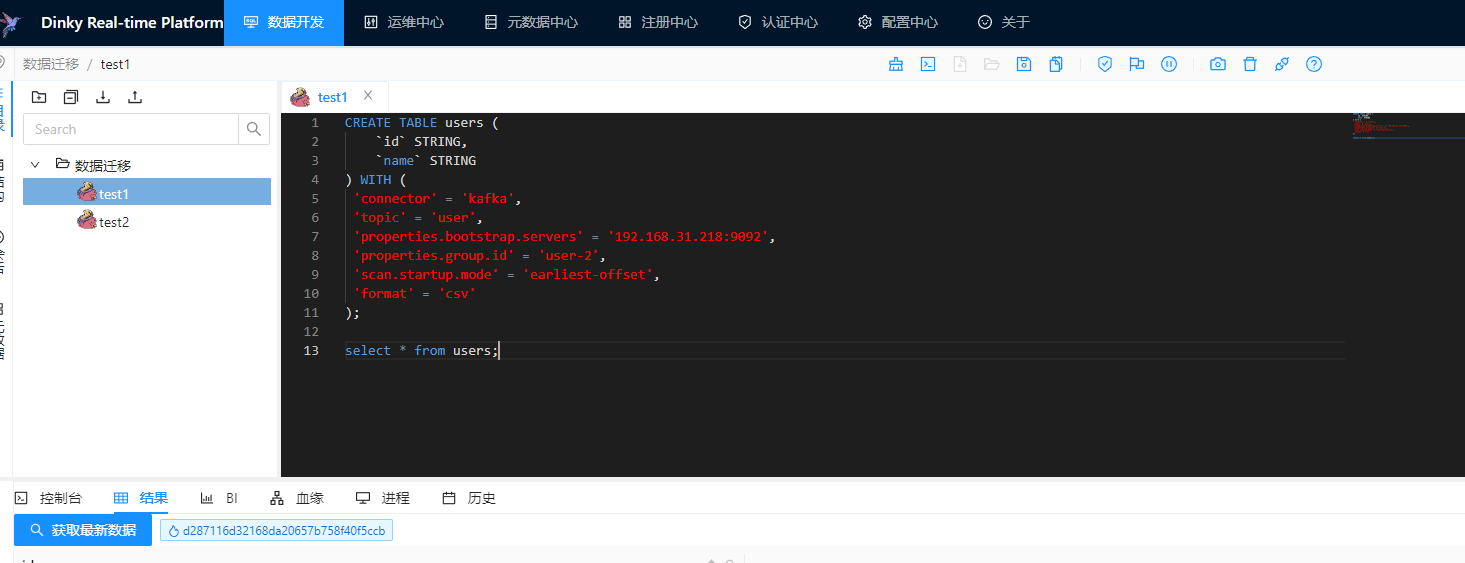
这里我们进入到dinky的数据开发目录下,创建一个名为test1的作业,然后创建一张users表,再查询下users的数据,具体的代码如下:
CREATE TABLE users ( `id` STRING, `name` STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'user', 'properties.bootstrap.servers' = '192.168.31.218:9092', 'properties.group.id' = 'user-2', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' ); select * from users;
完整代码示例图如下:
5)进入到kafka,模拟生产者发送数据
这时候由于我们这里没有现成的数据,可以模拟一个producer去生产符合users表的数据,这里的格式是csv,因此使用逗号进行分割,具体执行命令如下:
#启动生产者客户端 kafka-console-producer.sh --broker-list 192.168.31.218:9092 --topic user #发送数据 1,zhangsan 2,lisi 3,wangwu 4,zhaoliu
具体示例图如下:

6)执行flinksql作业,查看结果
此时我们继续回到dinky的作业界面,点击执行,然后在下方可以看到具体的结果
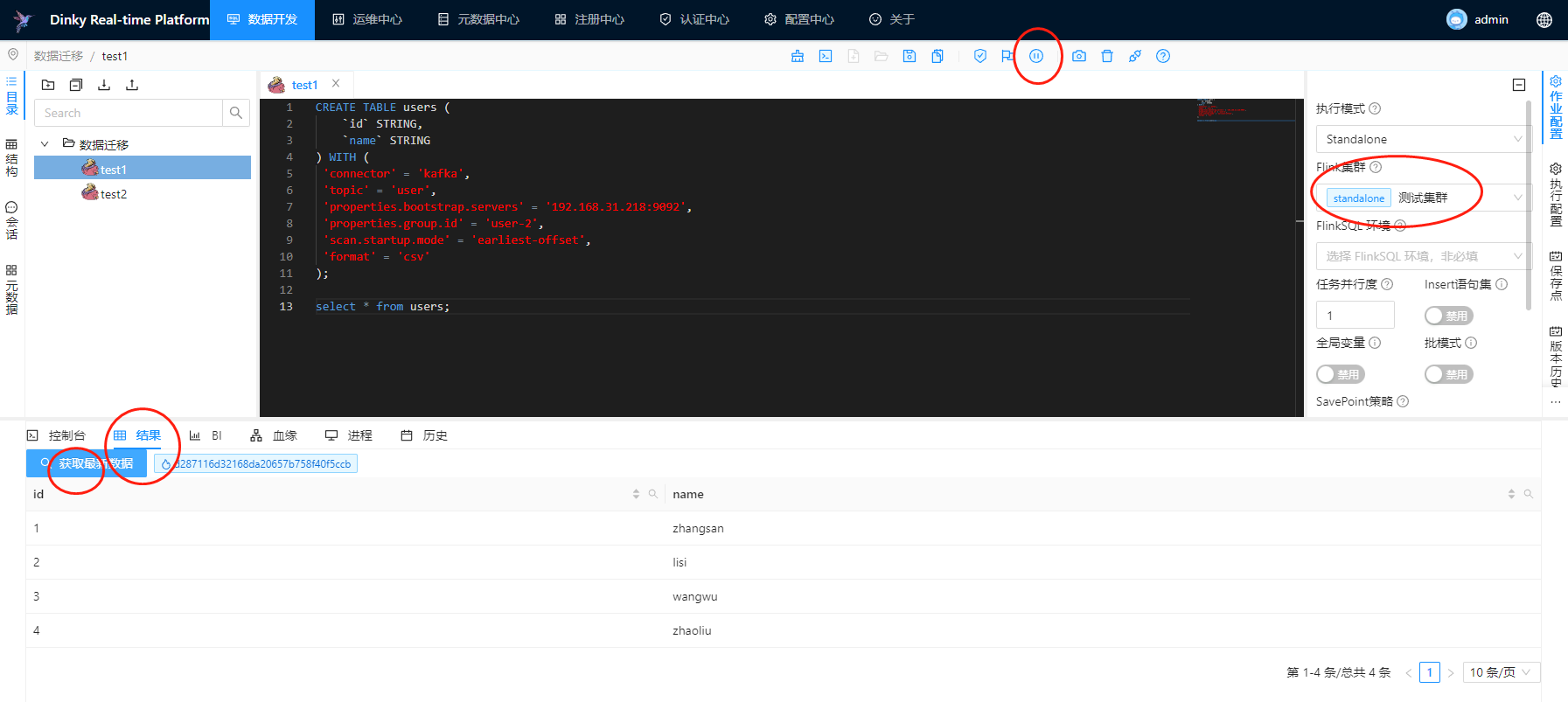
这里我们可以看到已经从kafka里面拿到了数据,此时我们再发送一条数据
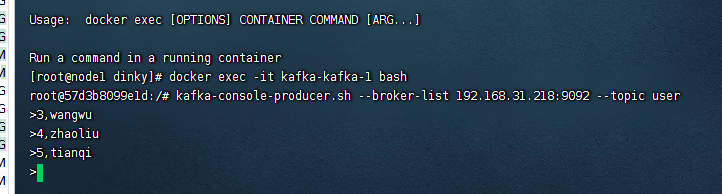
再回到dinky的界面,点击获取最新数据

可以看到最新生产的数据已经被查询出来了。由于flinksql对接kafka是属于流式的接收数据入库,所以我们可以近实时的形式查询到数据。



的超时时间或者重试次数")





还没有评论,来说两句吧...